Scrapeando las Sesiones Parlamentarias de Uruguay
Apr 3, 2018 · 2710 words · 13 minute read
En Uruguay venimos avanzando con las iniciativas de datos abiertos, pero aún queda mucho camino por recorrer. Algunas de las dificultades para analizar datos abiertos son:
-
Que no siempre no es fácil acceder a ellos de forma sistemática: por ejemplo porque no están todos juntos en un archivo comprimido para descargarlos, o no existe una API para acceder a la información,
-
Que están en formato pdf del que no es tan fácil extraer información como de un archivo txt o csv, por nombrar algunos formatos.
En particular hay dos problemas que quiero resolver:
-
Descargar los archivos en formato pdf de las Sesiones Parlamentarias de Diputados y Senadores de forma sistemática, haciendo lo que se conoce como web scraping.
-
Extraer el texto contenido en los archivos en formato pdf.
En este artículo muestro cómo se pueden sortear ambas dificultades, usando los paquetes rvest para explorar la web y descargar los Diarios de Sesiones, y pdftools para extraer el contenido de los archivos en formato pdf.
Está permitido que un robot se comunique con estas páginas?
Si bien se trata de datos abiertos, hay ciertas normas de etiqueta que es recomendable seguir. Respetar las reglas que establecieron los que administran el sitio acerca de cómo quieren que la gente lo use es una de ellas. Puede ser que sólo quieran que se navegue a mano, entonces no debería intentar acceder de la forma en que estoy planeando.
Para ver si la sección del sitio web que quiero navegar permite ser accedida por un robot (que es lo que pretendo construir! 🤖), examino el archivo robots.txt, donde se establece para cada sección del sitio si este uso es adecuado. Desde R se puede hacer fácilmente usando el parquete robotstxt de rOpenSci, que Maëlle mencionó en su post donde scrapea datos de The Guardian.
Este es todo el archivo robots.txt del sitio web del Parlamento:
robotstxt::get_robotstxt("https://parlamento.gub.uy")
## #
## # robots.txt
## #
## # This file is to prevent the crawling and indexing of certain parts
## # of your site by web crawlers and spiders run by sites like Yahoo!
## # and Google. By telling these "robots" where not to go on your site,
## # you save bandwidth and server resources.
## #
## # This file will be ignored unless it is at the root of your host:
## # Used: http://example.com/robots.txt
## # Ignored: http://example.com/site/robots.txt
## #
## # For more information about the robots.txt standard, see:
## # http://www.robotstxt.org/robotstxt.html
##
## User-agent: *
## Crawl-delay: 10
## # CSS, JS, Images
## Allow: /misc/*.css$
## Allow: /misc/*.css?
## Allow: /misc/*.js$
## Allow: /misc/*.js?
## Allow: /misc/*.gif
## Allow: /misc/*.jpg
## Allow: /misc/*.jpeg
## Allow: /misc/*.png
## Allow: /modules/*.css$
## Allow: /modules/*.css?
## Allow: /modules/*.js$
## Allow: /modules/*.js?
## Allow: /modules/*.gif
## Allow: /modules/*.jpg
## Allow: /modules/*.jpeg
## Allow: /modules/*.png
## Allow: /profiles/*.css$
## Allow: /profiles/*.css?
## Allow: /profiles/*.js$
## Allow: /profiles/*.js?
## Allow: /profiles/*.gif
## Allow: /profiles/*.jpg
## Allow: /profiles/*.jpeg
## Allow: /profiles/*.png
## Allow: /themes/*.css$
## Allow: /themes/*.css?
## Allow: /themes/*.js$
## Allow: /themes/*.js?
## Allow: /themes/*.gif
## Allow: /themes/*.jpg
## Allow: /themes/*.jpeg
## Allow: /themes/*.png
## # Directories
## Disallow: /includes/
## Disallow: /misc/
## Disallow: /modules/
## Disallow: /profiles/
## Disallow: /scripts/
## Disallow: /themes/
## # Files
## Disallow: /CHANGELOG.txt
## Disallow: /cron.php
## Disallow: /INSTALL.mysql.txt
## Disallow: /INSTALL.pgsql.txt
## Disallow: /INSTALL.sqlite.txt
## Disallow: /install.php
## Disallow: /INSTALL.txt
## Disallow: /LICENSE.txt
## Disallow: /MAINTAINERS.txt
## Disallow: /update.php
## Disallow: /UPGRADE.txt
## Disallow: /xmlrpc.php
## # Paths (clean URLs)
## Disallow: /admin/
## Disallow: /comment/reply/
## Disallow: /filter/tips/
## Disallow: /node/add/
## Disallow: /search/
## Disallow: /user/register/
## Disallow: /user/password/
## Disallow: /user/login/
## Disallow: /user/logout/
## # Paths (no clean URLs)
## Disallow: /?q=admin/
## Disallow: /?q=comment/reply/
## Disallow: /?q=filter/tips/
## Disallow: /?q=node/add/
## Disallow: /?q=search/
## Disallow: /?q=user/password/
## Disallow: /?q=user/register/
## Disallow: /?q=user/login/
## Disallow: /?q=user/logout/
Lo que no aparece como “Disallow” es permitido por defecto, y la url a la que quiero acceder usando un robot es https://parlamento.gub.uy/documentosyleyes/documentos/diarios-de-sesion. No dice en ningún lugar del documento Disallow: /documentosyleyes/, entonces está permitido!
Pero por las dudas, chequeo esa url en particular:
robotstxt::paths_allowed("https://parlamento.gub.uy/documentosyleyes/documentos/diarios-de-sesion")
## [1] TRUE
Tengo luz verde para scrapear la web 🙌.
Url de las páginas que quiero scrapear
Mi intención es descargar las sesiones de Diputados y Senadores desde el 1º/1/2017 hasta el 31/3/2018. Al incorporar estos filtros manualmente en la página https://parlamento.gub.uy/documentosyleyes/documentos/diarios-de-sesion, la url se va modificando para incorporar esta información. Eso hace las cosas algo menos complicadas para mi, porque una vez que me doy cuenta cómo se comporta la url con esos filtros, puedo generar la url nueva y directamente acceder a ella. Así construyo la nueva url que se compone de la url original, algo de texto adicional y los filtros de fechas, de la siguiente forma:
date_init <- "01-01-2017"
date_end <- "31-03-2018"
url_diputados <- paste0("https://parlamento.gub.uy/documentosyleyes/documentos/diarios-de-sesion?Cpo_Codigo_2=D&Lgl_Nro=48&DS_Fecha%5Bmin%5D%5Bdate%5D=",
date_init,
"&DS_Fecha%5Bmax%5D%5Bdate%5D=",
date_end,
"&Ssn_Nro=&TS_Diario=&tipoBusqueda=T&Texto=")
url_diputados
## [1] "https://parlamento.gub.uy/documentosyleyes/documentos/diarios-de-sesion?Cpo_Codigo_2=D&Lgl_Nro=48&DS_Fecha%5Bmin%5D%5Bdate%5D=01-01-2017&DS_Fecha%5Bmax%5D%5Bdate%5D=31-03-2018&Ssn_Nro=&TS_Diario=&tipoBusqueda=T&Texto="
url_senadores <- paste0("https://parlamento.gub.uy/documentosyleyes/documentos/diarios-de-sesion?Cpo_Codigo_2=S&Lgl_Nro=48&DS_Fecha%5Bmin%5D%5Bdate%5D=",
date_init,
"&DS_Fecha%5Bmax%5D%5Bdate%5D=",
date_end,
"&Ssn_Nro=&TS_Diario=&tipoBusqueda=T&Texto=")
url_senadores
## [1] "https://parlamento.gub.uy/documentosyleyes/documentos/diarios-de-sesion?Cpo_Codigo_2=S&Lgl_Nro=48&DS_Fecha%5Bmin%5D%5Bdate%5D=01-01-2017&DS_Fecha%5Bmax%5D%5Bdate%5D=31-03-2018&Ssn_Nro=&TS_Diario=&tipoBusqueda=T&Texto="
Y ahora? Cómo selecciono el contenido de la página?
Las páginas web son archivos html que el navegador interpreta y los transforma en lo que nosotros vemos. No voy a entrar en muchos detalles de cómo interpretar un archivo html (porque recién estoy aprendiendo!), pero acá describo la forma más intuitiva que encontré para seleccionar el contenido del html al que quiero acceder.
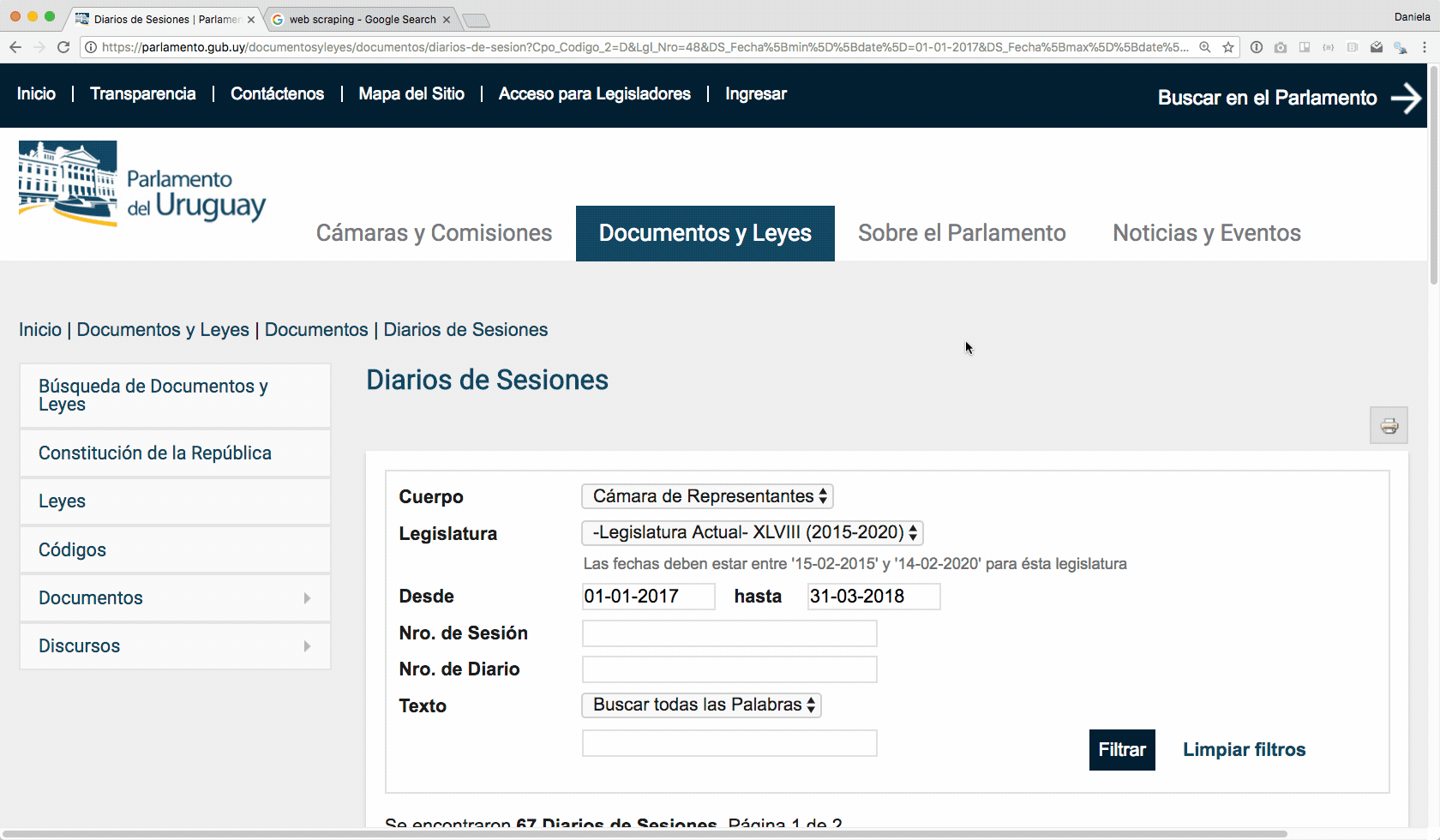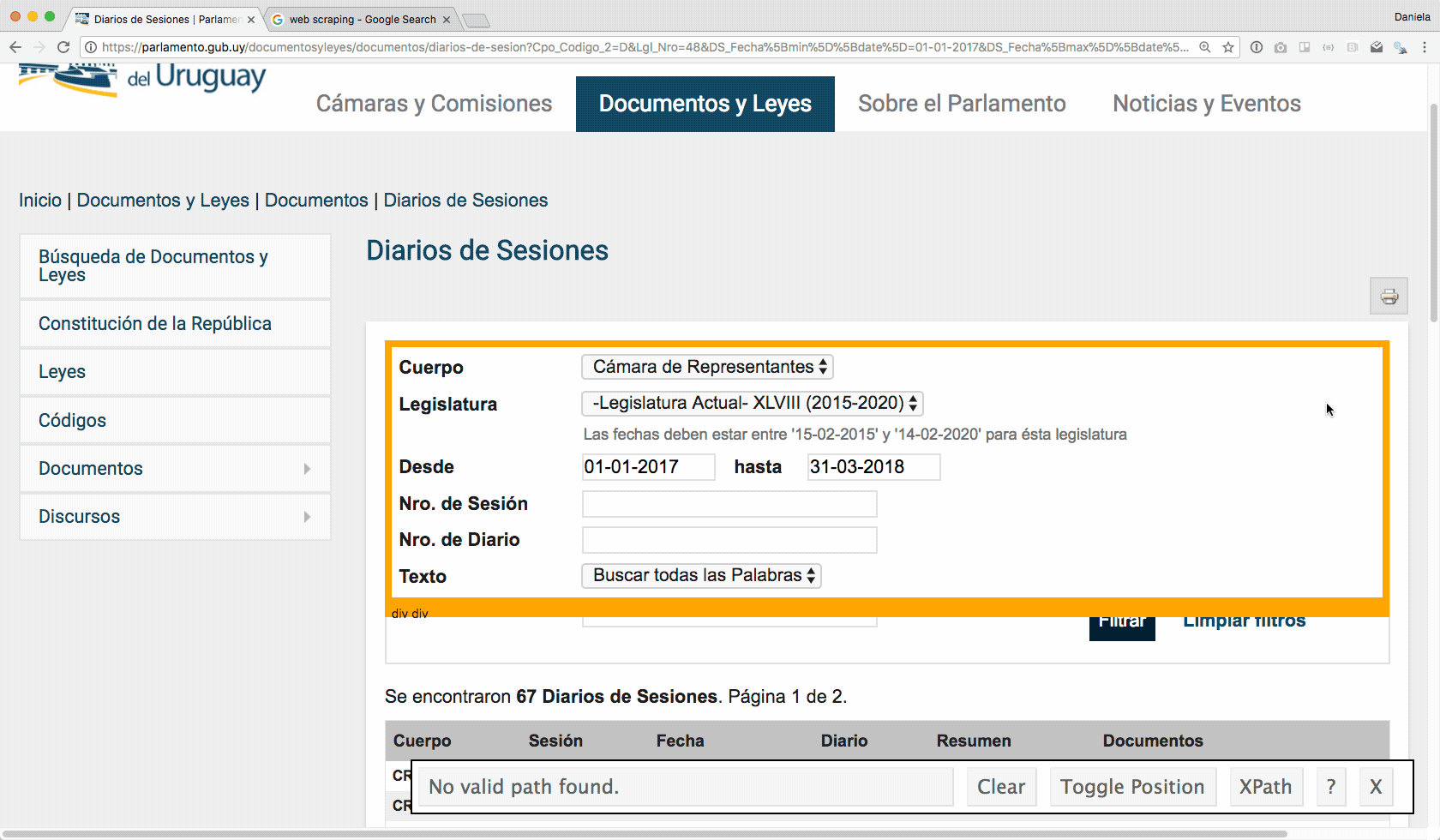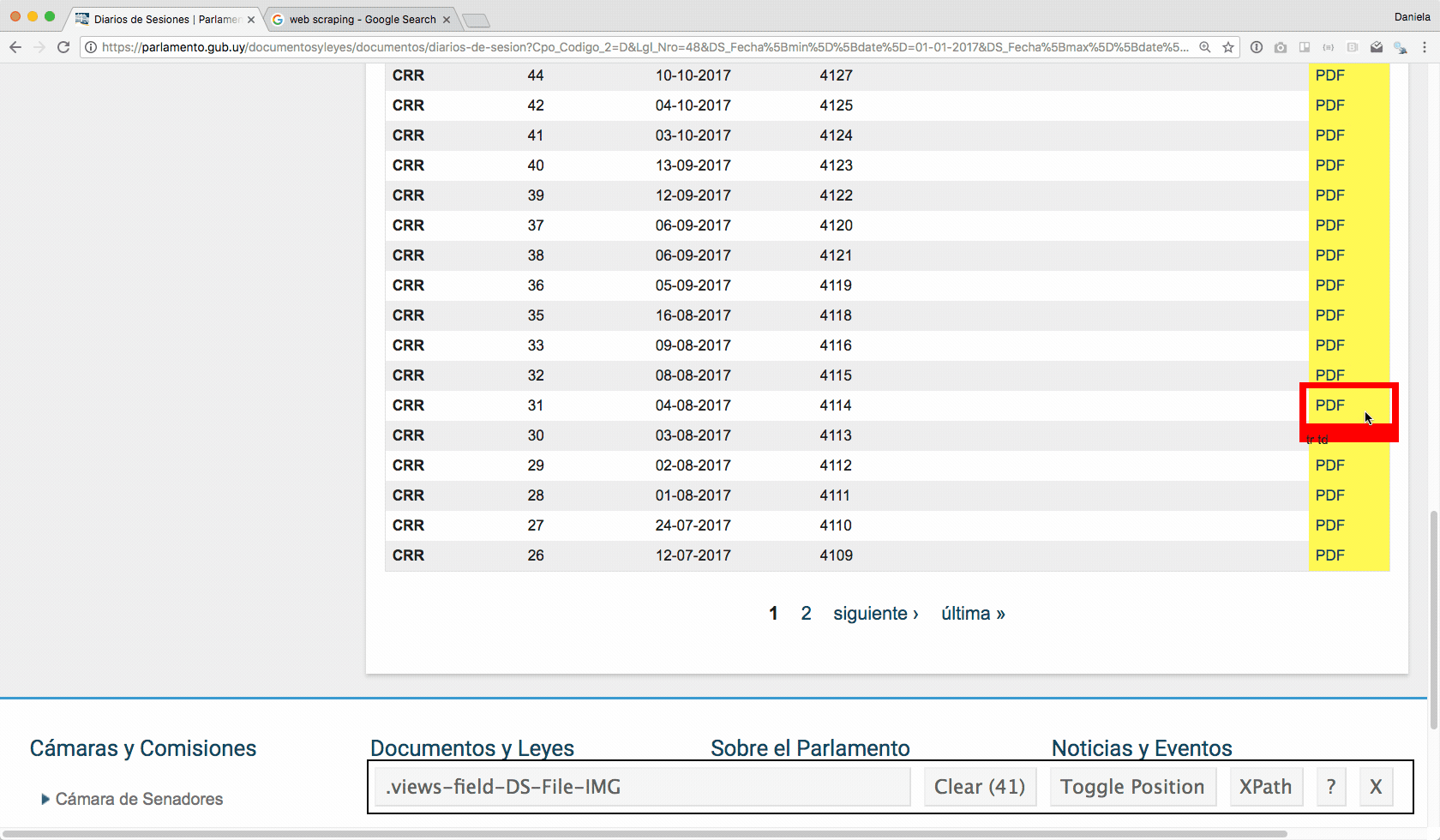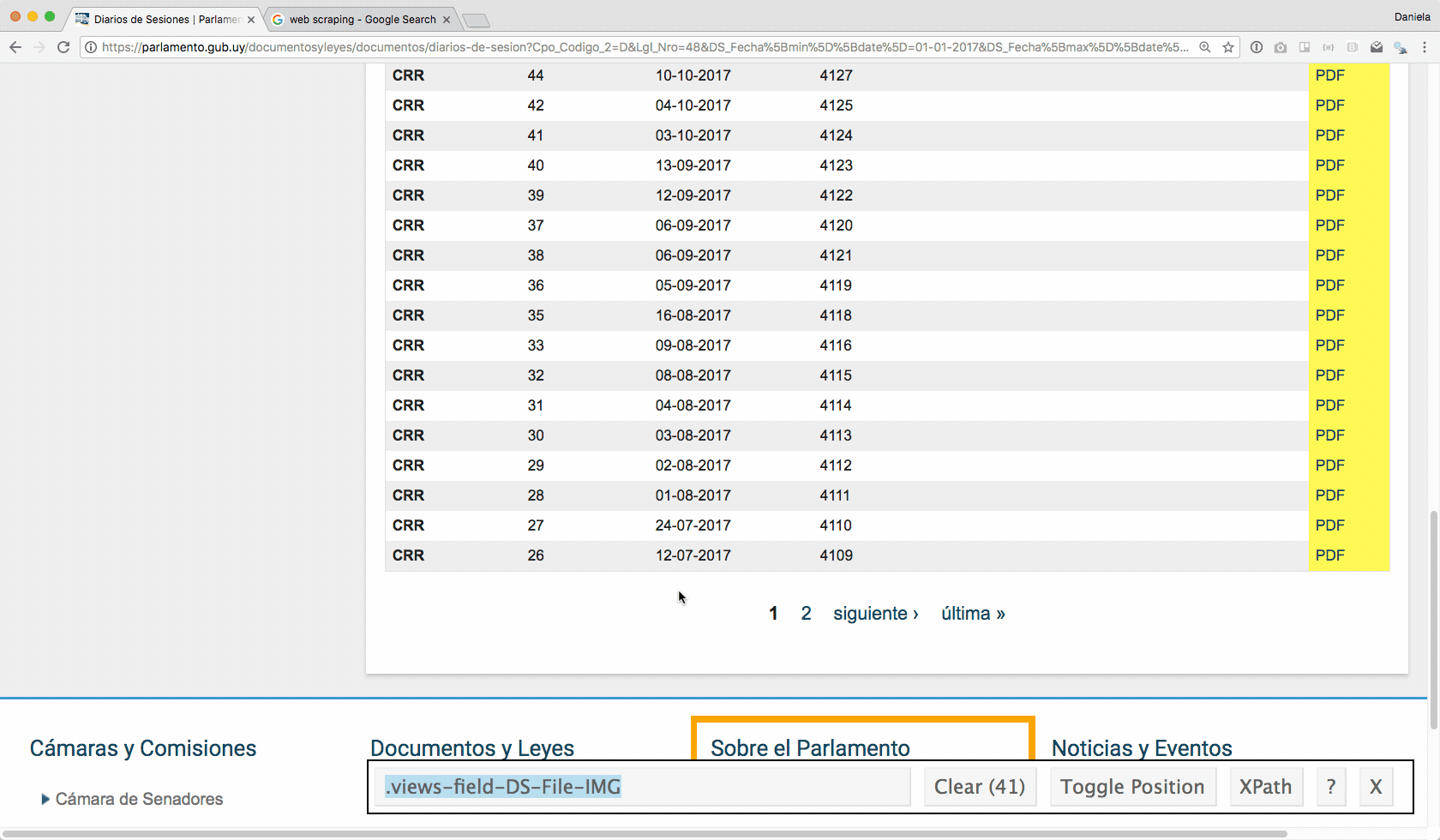
Como se muestra en la animación a continuación, usando el Selector Gadget (que tiene una extensión para Google Chrome muy conveniente) me paro con el mouse sobre uno de los links a los pdfs y hago click. Ahí queda pintada toda la columna, porque pinta todos los elementos que son de la misma clase (no nos preocupemos de qué es una clase ahora). Lo importante es que necesito el nombre de la clase para lo que viene a continuación, entonces copio el texto que aparece en el recuadro (en este caso es .views-field-DS-File-IMG).
Web scraping!
Extraigo los pdfs
Ahora es que empiezo a usar el paquete rvest. Defino una función que descarga los pdfs y los guarda en un dataframe, haciendo algunas transformaciones. Para explicar lo que hace la función voy a ignorar que como las sesiones son muchas, las muestra en dos páginas separadas. Es verdad que podría haber puesto un poco más de esfuerzo en hacer esta función generalizable a n páginas, pero como sabía que tenía sólo 2, lo dejé así 😇
library(dplyr)
library(rvest)
library(purrr)
library(tibble)
library(pdftools)
extract_pdf <- function(url, pag = 1) {
if (pag == 2) {
url <- url %>%
read_html() %>%
html_nodes(".pager-item a") %>%
html_attr("href") %>%
map(~ paste0("https://parlamento.gub.uy", .)) %>%
unlist()
}
pdfs <- url %>%
read_html() %>%
html_nodes(".views-field-DS-File-IMG a") %>% # seleccionar clase
html_attr("href") %>%
map(~ paste0("https://parlamento.gub.uy", .)) %>%
map(~ paste0(pdf_text(.), collapse = ' ')) %>%
map(~ stri_trans_general(tolower(.), id = "latin-ascii")) %>%
map(~ stri_replace_all(., replacement = "", regex = "\\\n")) %>%
map_df(function(pdf) {tibble(pdf)})
return(pdfs)
}
La primera parte de la función es la que voy a ignorar, donde lo que hago es modificar la url para indicar que quiero ir a la segunda página (se puede aplicar la misma lógica que la que voy a usar a continuación para interpretar esta parte del código).
Lo interesante pasa cuando empiezo a procesar la url: read_html() “lee” el contenido de la página, para que pueda buscar lo que me interesa. Mi objetivo es encontrar todos los archivos pdf (por eso me interesaba conocer el nombre de la clase de esos elementos, que descubrí antes). Con html_nodes() voy extrayendo los nodos (tampoco nos preocupemos ahora por saber qué son exactamente), y en este caso el nodo que me interesa es .views-field-DS-File-IMG a:
-
tiene un punto adelante para indicar que se trata de elementos de una clase, seguido del nombre de la clase
views-field-DS-File-IMG(lo que copiamos con el Selector Gadget), -
aes la etiqueta que html usa para definir elementos que son un hipervínculo.
Ahora puedo seleccionar el atributo href, que es el link al pdf, con la función html_attr(). Acá hay que tener cuidado porque la ruta es relativa (es decir que falta poner “https://parlamento.gub.uy" antes para tener la ruta completa).
Al aplicar la función hasta acá, lo que tengo es una lista con una url por cada pdf que aparece en la página. Por eso luego uso la función purrr::map() para aplicar a cada elemento de la lista (cada link a los pdfs), una función. Las transformaciones que aplico a cada elemento de la lista son, en forma sucesiva, las siguientes:
-
paste0("https://parlamento.gub.uy", .)completo la ruta absoluta, pegando “https://parlamento.gub.uy" adelante del link relativo, -
paste0(pdf_text(.), collapse = ' ')usando el paquetepdftoolsextraigo la información del pdf con la funciónpdf_text()y colapso todas las páginas en un mismo string, -
stri_trans_general(tolower(.), id = "latin-ascii")saco los caracteres especiales y dejo todo en minúscula, -
stri_replace_all(., replacement = "", regex = "\\\n")elimino los saltos de línea, -
tibble(pdf)transformo la lista en un dataframe.
Entonces ahora extraigo los pdfs de las dos páginas y los junto en un único dataframe (voy a mostrar el proceso para Diputados, pero es análogo para Senadores).
pdf_diputados_pag1 <- extract_pdf(url_diputados, pag = 1)
pdf_diputados_pag2 <- extract_pdf(url_diputados, pag = 2)
pdf_diputados <- bind_rows(pdf_diputados_pag1, pdf_diputados_pag2)
library(knitr)
library(kableExtra)
knitr::kable(head(pdf_diputados) %>%
select(pdf) %>%
mutate(pdf = substr(pdf, start=1, stop=500)),
format = "html")
| numero 4151 montevideo, miercoles 14 de marzo de 2018 republica oriental del uruguay diario de sesiones camara de representantes 5ª sesion (extraordinaria) preside el senor representante jorge gandini (presidente) |
| numero 4148 montevideo, martes 6 de marzo de 2018 republica oriental del uruguay diario de sesiones camara de representantes 2ª sesion presiden los senores representantes jorge gandini (presidente) |
| numero 4147 montevideo, jueves 1° de marzo de 2018 republica oriental del uruguay diario de sesiones camara de representantes 1ª sesion preside el senor representante jorge gandini (presidente) |
| numero 4146 montevideo, jueves 8 de febrero de 2018 republica oriental del uruguay diario de sesiones camara de representantes 3ª sesion (extraordinaria) presiden los senores representantes prof. jose carlos mahia (preside |
| numero 4145 montevideo, miercoles 7 de febrero de 2018 republica oriental del uruguay diario de sesiones camara de representantes 2ª sesion (extraordinaria) preside el senor representante prof. jose carlos mahia (presidente) actuan en secret |
| numero 4144 montevideo, miercoles 20 de diciembre de 2017 republica oriental del uruguay diario de sesiones camara de representantes 1ª sesion (extraordinaria) presiden los senores representantes prof. jose carlos mahia (presi |
⚠️ Advertencia ⚠️
La función pdftools::read_pdf() lee los renglones de izquierda a derecha. En los Diarios de Sesiones hay algunas páginas que se organizan con texto en dos columnas, entonces hay renglones que, leídos de esa forma, quedan incoherentes. Esto hay que tenerlo en cuenta para ver si el tipo de análisis que quiero hacer tiene sentido o no. Por ejemplo, si lo que quiero es analizar n-gramas donde el orden de las palabras es importante, voy a tener problemas porque estaría considerando palabras de distintas columnas de texto, como si vinieran una a continuación de la otra. Para analizar sentimiento con bolsa de palabras (bag of words) no hay problema, porque el orden de las palabras no es relevante.
Extraigo fecha y número de sesión
Hago una segunda función para extraer otros la fecha y el número de la sesión, porque se puede dar el caso de tener más de una sesión en la misma fecha.
extract_metadata <- function(url, info, pag = 1){
if (info == "fecha") nodes = "td.views-field-DS-Fecha"
if (info == "sesion") nodes = "td.views-field-Ssn-Nro"
if (pag == 2){
url <- url %>%
read_html() %>%
html_nodes(".pager-item a") %>%
html_attr("href") %>%
map(~ paste0("https://parlamento.gub.uy", .)) %>%
unlist()
}
url %>%
read_html() %>%
html_nodes(nodes) %>%
html_text() %>%
map(~str_extract(., "[0-9\\-]+")) %>% # esta expresión regular matchea tanto la fecha como el número de sesión
unlist()
}
Extraigo la fecha y la sesión.
# extraigo fechas
pdf_fechas_diputados_pag1 <- extract_metadata(url_diputados, info = "fecha", pag = 1)
pdf_fechas_diputados_pag2 <- extract_metadata(url_diputados, info = "fecha", pag = 2)
# junto todos las fechas y las convierto en un df
pdf_fechas_diputados <- c(pdf_fechas_diputados_pag1, pdf_fechas_diputados_pag2) %>%
tbl_df() %>%
transmute(fecha = as.Date(value, "%d-%m-%Y"))
# extraigo sesiones
pdf_sesion_diputados_pag1 <- extract_metadata(url_diputados, info = "sesion", pag = 1)
pdf_sesion_diputados_pag2 <- extract_metadata(url_diputados, info = "sesion", pag = 2)
# junto todos las sesiones y las convierto en un df
pdf_sesion_diputados <- c(pdf_sesion_diputados_pag1, pdf_sesion_diputados_pag2) %>%
tbl_df() %>%
rename(sesion = value)
knitr::kable(head(pdf_sesion_diputados) %>% select(fecha),
format = "html")
| fecha |
|---|
| 2018-03-14 |
| 2018-03-06 |
| 2018-03-01 |
| 2018-02-08 |
| 2018-02-07 |
| 2017-12-20 |
knitr::kable(head(pdf_sesion_diputados) %>% select(sesion),
format = "html")
| sesion |
|---|
| 5 |
| 2 |
| 1 |
| 3 |
| 2 |
| 1 |
diputados <- bind_cols(pdf_fechas_diputados, pdf_sesion_diputados, pdf_diputados) %>%
unite("fecha_sesion", c(fecha, sesion), remove = FALSE) %>%
distinct() # la primer sesión de la segunda página es igual a la última sesión de la primera página
Con este dataframe es con el que voy a trabajar para los Diputados, que tiene 66 sesiones.
knitr::kable(head(diputados) %>%
mutate(pdf = substr(pdf, start=1, stop=500)),
format = "html")
| fecha_sesion | fecha | sesion | |
|---|---|---|---|
| 2018-03-14_5 | 2018-03-14 | 5 | numero 4151 montevideo, miercoles 14 de marzo de 2018 republica oriental del uruguay diario de sesiones camara de representantes 5ª sesion (extraordinaria) preside el senor representante jorge gandini (presidente) |
| 2018-03-06_2 | 2018-03-06 | 2 | numero 4148 montevideo, martes 6 de marzo de 2018 republica oriental del uruguay diario de sesiones camara de representantes 2ª sesion presiden los senores representantes jorge gandini (presidente) |
| 2018-03-01_1 | 2018-03-01 | 1 | numero 4147 montevideo, jueves 1° de marzo de 2018 republica oriental del uruguay diario de sesiones camara de representantes 1ª sesion preside el senor representante jorge gandini (presidente) |
| 2018-02-08_3 | 2018-02-08 | 3 | numero 4146 montevideo, jueves 8 de febrero de 2018 republica oriental del uruguay diario de sesiones camara de representantes 3ª sesion (extraordinaria) presiden los senores representantes prof. jose carlos mahia (preside |
| 2018-02-07_2 | 2018-02-07 | 2 | numero 4145 montevideo, miercoles 7 de febrero de 2018 republica oriental del uruguay diario de sesiones camara de representantes 2ª sesion (extraordinaria) preside el senor representante prof. jose carlos mahia (presidente) actuan en secret |
| 2017-12-20_1 | 2017-12-20 | 1 | numero 4144 montevideo, miercoles 20 de diciembre de 2017 republica oriental del uruguay diario de sesiones camara de representantes 1ª sesion (extraordinaria) presiden los senores representantes prof. jose carlos mahia (presi |
Y con este dataframe es con el que voy a trabajar para los Senadores, que tiene 59 sesiones.
knitr::kable(head(senadores) %>%
mutate(pdf = substr(pdf, start=1, stop=500)),
format = "html")
| fecha_sesion | fecha | sesion | |
|---|---|---|---|
| 2018-03-06_1 | 2018-03-06 | 1 | n.º 1 - tomo 578 6 de marzo de 2018 republica oriental del uruguay diario de sesiones de la camara de senadores cuarto periodo de la xlviii legislatura |
| 2018-02-27_57 | 2018-02-27 | 57 | n.º 57 - tomo 577 27 de febrero de 2018 republica oriental del uruguay diario de sesiones de la camara de senadores tercer periodo de la xlviii legislatura 57 |
| 2018-02-21_56 | 2018-02-21 | 56 | n.º 56 - tomo 577 21 de febrero de 2018 republica oriental del uruguay diario de sesiones de la camara de senadores tercer periodo de la xlviii legislatura 56.ª |
| 2018-02-07_55 | 2018-02-07 | 55 | n.º 55 - tomo 577 7 de febrero de 2018 republica oriental del uruguay diario de sesiones de la camara de senadores tercer periodo de la xlviii legislatura 55. |
| 2018-02-06_54 | 2018-02-06 | 54 | n.º 54 - tomo 577 6 de febrero de 2018 republica oriental del uruguay diario de sesiones de la camara de senadores tercer periodo de la xlviii legislatura 54.ª s |
| 2017-12-27_53 | 2017-12-27 | 53 | n.º 53 - tomo 577 27 de diciembre de 2017 republica oriental del uruguay diario de sesiones de la camara de senadores tercer periodo de la xlviii legislatura 53.ª se |
Tadá 🎉
Ahora con los datos en este formato, estoy en condiciones de analizar las sesiones!
Para más información acerca de cómo trabajar con datos de la web, hay un tutorial de Arvid Kingl en Datacamp en inglés para usar rvest y hay un curso de Charlotte Wickham y Oliver Keyes, también en inglés y en Datacamp, que habla además de otras formas de consumir datos de la web, como a través de APIs.
Si querés analizar las sesiones fuera de R, o preferís ahorrarte el paso de hacer scraping, acá tenés las sesiones de Diputados en formato csv, y acá las sesiones de Senadores en formato csv para hacer tus análisis! (Gracias Rodrigo por la sugerencia!)
Todo lo que usé en este artículo (y más!) está disponible en GitHub. Espero que haya resultado útil! Dejame tus comentarios abajo o mencioname en Twitter 😃