¿De qué se habló en el Parlamento uruguayo desde 2017?
Apr 8, 2018 · 2291 words · 11 minute read
En el artículo pasado mostré cómo se pueden obtener los textos de los Diarios de Sesiones. Primero obtuve los archivos pdf haciendo web scraping y después extraje los textos de esos archivos.
Ahora que tengo los datos, en este artículo analizo el texto de las sesiones de Diputados y Senadores desde 2017 usando el paquete tidytext, centrándome en el sentimiento y en identificar los temas tratados.
Levanto los datos
Levanto los datos que obtuve del scraping de mi repositorio de GitHub y les saco los saltos de línea (los dejé porque para algún análisis podría servir tenerlos).
library(dplyr)
library(stringi)
url_rds_diputados <- 'https://github.com/d4tagirl/uruguayan_parliamentary_session_diary/raw/master/data/pdf_diputados'
diputados <- readRDS(url(url_rds_diputados))
url_rds_senadores <- 'https://github.com/d4tagirl/uruguayan_parliamentary_session_diary/raw/master/data/pdf_senadores'
senadores <- readRDS(url(url_rds_senadores))
# saco los saltos de linea
diputados <- diputados %>%
mutate(pdf = stri_replace_all(pdf, replacement = "", regex = "\\\n"))
senadores <- senadores %>%
mutate(pdf = stri_replace_all(pdf, replacement = "", regex = "\\\n"))
Con qué frecuencia se reunieron?
Como quiero averiguar la cantidad de sesiones por mes-año, porque tengo más de un mes de enero (el enero de 2017 y el de 2018), busqué y me quedé muy contenta de encontrar la función zoo::as.yearmon() que extrae exactamente esa información de una fecha!
library(ggplot2)
library(scales)
library(zoo)
library(lubridate)
freq_diputados <- ggplot(diputados, aes(as.factor(as.yearmon(fecha)), fill=as.factor(as.yearmon(fecha)))) +
geom_bar(position='dodge', show.legend = FALSE) +
ylab("Cantidad") +
xlab("") +
scale_x_discrete(limits = as.factor(as.yearmon(seq.Date(floor_date(min(diputados$fecha), "month"),
floor_date(max(diputados$fecha), "month"), "month")))) +
theme_minimal() +
theme(axis.text.x=element_blank()) +
ggtitle("Sesiones de Diputados")
freq_senadores <- ggplot(senadores, aes(as.factor(as.yearmon(fecha)), fill=as.factor(as.yearmon(fecha)))) +
geom_bar(position='dodge', show.legend = FALSE) +
xlab("") +
ylab("Cantidad") +
scale_x_discrete(limits = as.factor(as.yearmon(seq.Date(floor_date(min(senadores$fecha), "month"), floor_date(max(senadores$fecha), "month"), "month")))) +
theme_minimal() +
theme(axis.text.x = element_text(angle=45,
hjust = 1,
vjust = 1)) +
ggtitle("Sesiones de Senadores")
library(gridExtra)
grid.arrange(freq_diputados, freq_senadores)
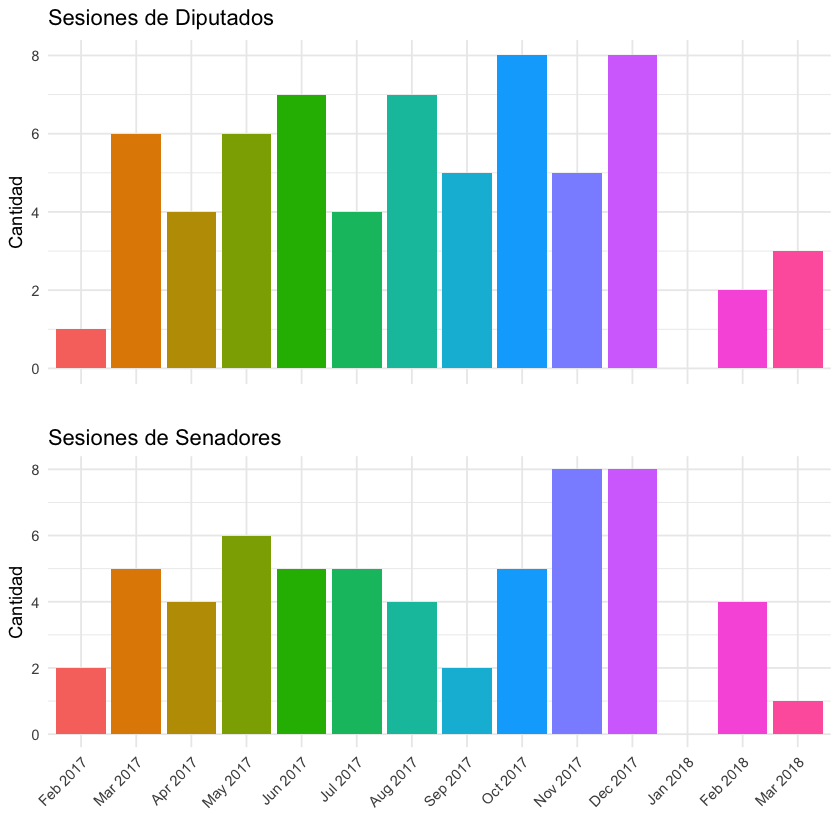
Según esta nota de “En Perspectiva” que encontré, “El régimen de sesiones ordinarias, […] en ambas Cámaras se desarrollan los días martes y miércoles, entre el 1º y el 18 de cada mes. […] luego del día 18 puede haber sesiones extraordinarias, donde se considera cualquier tema." Según mis cálculos tiene que haber como mínimo entre 4 y 6 sesiones mensuales. Los diputados lo cumplieron todos los meses exceptuando enero de 2017, febrero de ambos años y marzo de 2018 (meses asociados al verano y las licencias). Los Senadores lo cumplieron todos los meses exceptuando febrero de 2017, setiembre de 2017 (quizás vacaciones de primavera?), enero de 2018 y marzo de 2018. Sospecho que aún no subieron todas las sesiones de marzo de 2018 y por eso aparecen tan pocas sesiones para ambas Cámaras.
Tanto Diputados como Senadores tuvieron un máximo de sesiones mensuales de 8, con una frecuencia mayor entre marzo y diciembre. Diciembre, como ya sospechaba, es un mes ocupado en el Parlamento.
Qué tan largas fueron las sesiones?
Asumir que la cantidad de palabras en una sesión es una buena forma de aproximarme a la duración de la sesión, parece bastante razonable. Nunca estuve en una sesión, pero no me imagino a los parlamentarios reunidos y sin hablar 🗣️
Primero transformo los datos para generar un dataframe con la cantidad de palabras en promedio por sesión en cada mes (lo muestro para diputados, es análogo para senadores).
library(tidytext)
# calculo las palabras por mes
sesion_diputados_words_mes <- diputados %>%
unnest_tokens(word, pdf) %>%
mutate(mes = as.yearmon(fecha)) %>%
count(mes, sort = TRUE) %>%
ungroup()
# calculo la cantidad de sesiones por mes
cant_sesiones_diputados_mes <- diputados %>%
group_by(mes = as.yearmon(fecha)) %>%
summarise(cant_sesiones = n()) %>%
ungroup()
# los junto
sesion_diputados_words_mes <- left_join(sesion_diputados_words_mes, cant_sesiones_diputados_mes) %>%
mutate(palabras_prom_sesion = n/cant_sesiones)
Y ahora los grafico:
prom_palabras_sesiones_diputados <- ggplot(sesion_diputados_words_mes, aes(x = as.factor(mes), fill=as.factor(mes))) +
geom_col(aes(y = palabras_prom_sesion), show.legend = FALSE) +
scale_y_continuous(limit=c(0,150000)) +
ylab("Cantidad de palabras promedio\nde las sesiones del mes") +
xlab("") +
scale_x_discrete(limits = as.factor(as.yearmon(seq.Date(floor_date(min(senadores$fecha), "month"),
floor_date(max(senadores$fecha), "month"), "month")))) +
theme_minimal() +
theme(axis.text.x=element_blank()) +
ggtitle("Cantidad de palabras promedio en sesiones de Diputados")
prom_palabras_sesiones_senadores <- ggplot(sesion_senadores_words_mes, aes(x = as.factor(mes), fill=as.factor(mes))) +
geom_col(aes(y = palabras_prom_sesion), show.legend = FALSE) +
scale_y_continuous(limit=c(0,150000)) +
scale_x_discrete(limits = as.factor(as.yearmon(seq.Date(floor_date(min(senadores$fecha), "month"),
floor_date(max(senadores$fecha), "month"), "month")))) +
xlab("") +
ylab("Cantidad de palabras promedio\nde las sesiones del mes") +
theme_minimal() +
theme(axis.text.x = element_text(angle=45,
hjust = 1,
vjust = 1)) +
ggtitle("Cantidad de palabras promedio en sesiones de Senadores")
grid.arrange(prom_palabras_sesiones_diputados, prom_palabras_sesiones_senadores)
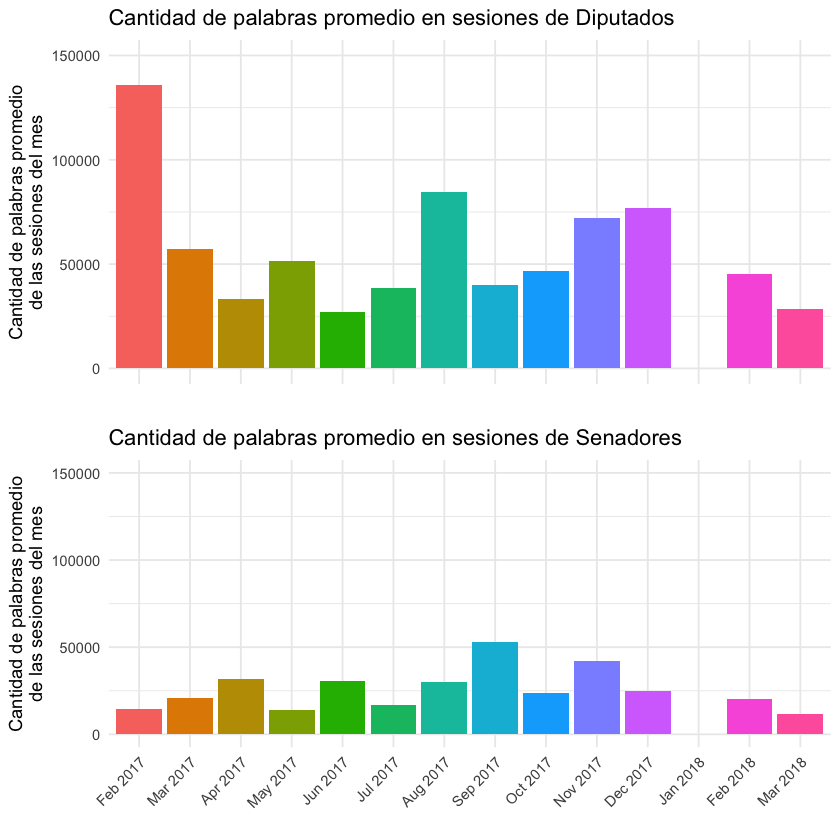
Hubo una sola sesion de diputados en febrero de 2017, pero fue mucho más extensa que las demás. Después vamos a ver que tuvo que ver con la interpelación del Ministro del Interior Eduardo Bonomi por una situación de extrema violencia en el fútbol.
Además en las sesiones de senadores se habló menos (probablemente sean más cortas). Tiene sentido porque son 30 los senadores, mientras que los diputados son 99!
Palabras más comúnes
Las palabras más comúnes de todas las sesiones de ambas Cámaras son las que aparecen a continuación (como siempre, muestro el código para Diputados, y para Senadores es análogo).
Para contar palabras, es buena práctica sacar las palabras comúnes como “y”, “el”, “es”, comúnmente llamadas “stopwords”. No hay tantos diccionarios disponibles para español como para inglés, pero algunos hay! Acá voy a usar las stopwords incluidas en el paquete rcorpora para español.
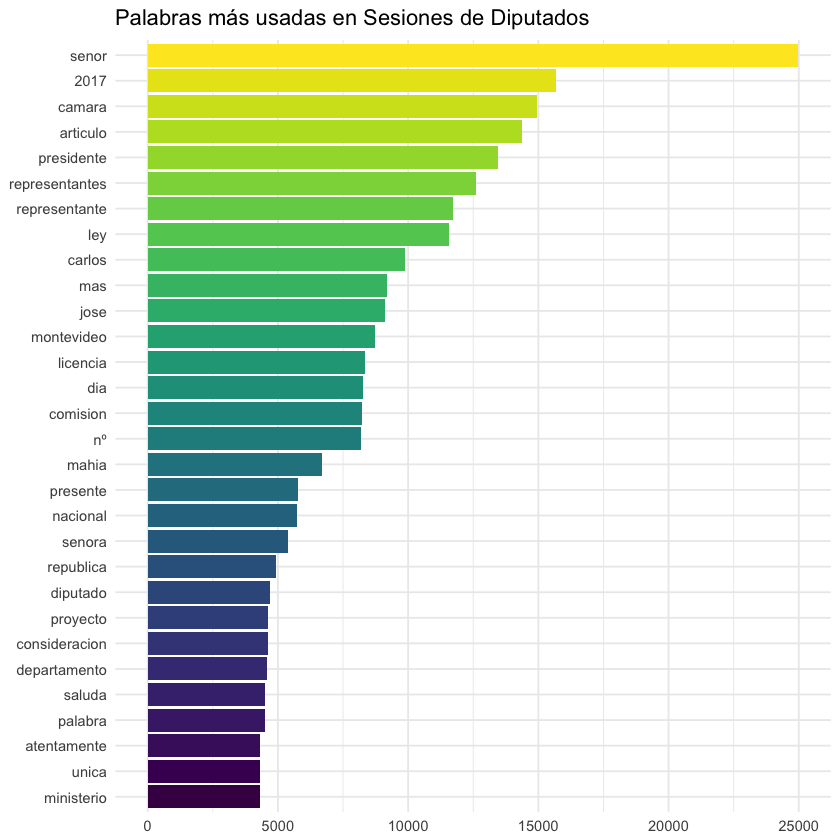
Las palabras más usadas en las Sesiones de Diputados:
library(rcorpora)
library(viridis)
stopwords <- corpora("words/stopwords/es")$stopWords
stopwords <- c(stopwords, as.character(seq(1:50)))
# Diputados
tidy_diputados <- diputados %>%
tidytext::unnest_tokens(word, pdf) %>%
filter(!word %in% stopwords)
most_used_dip <- tidy_diputados %>%
count(word, sort = TRUE) %>%
ungroup()
most_used_dip %>%
top_n(30) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = word)) +
geom_col(show.legend = FALSE) +
coord_flip() +
theme_minimal() +
theme(axis.title.y =element_blank() , axis.title.x =element_blank()) +
scale_fill_viridis(discrete = TRUE) +
ggtitle("Palabras más usadas en Sesiones de Diputados")
Las más usadas en las Sesiones de Senadores:
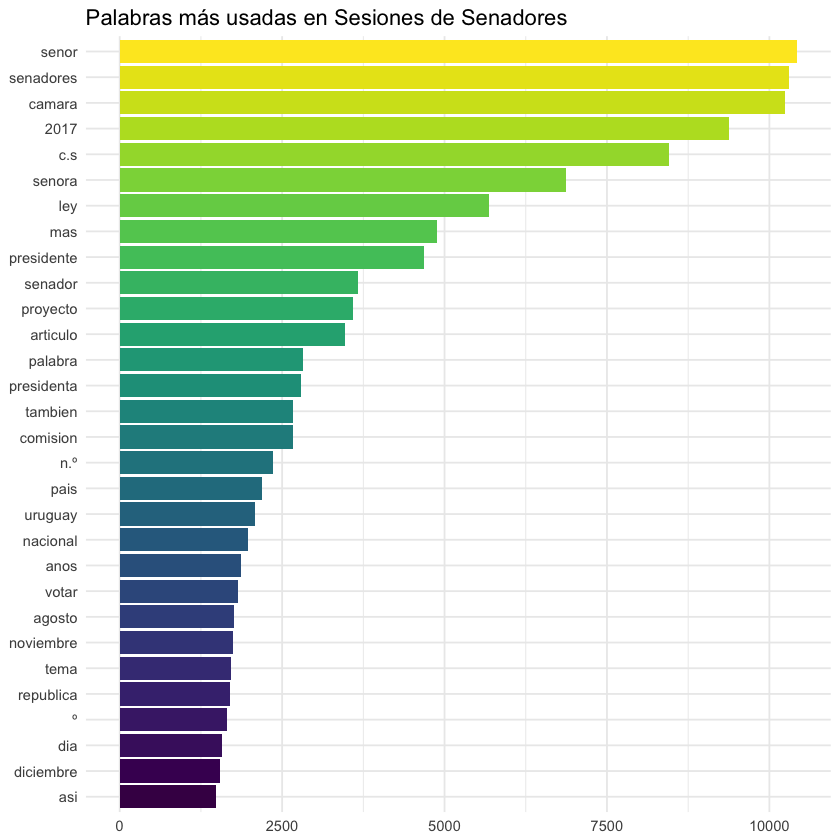
No nos dice mucho esta información: son palabras que protocolarmente se utilizan en estos entornos, así como nombres de políticos. Para lo único que nos sirve es para confirmar que efectivamente tiene sentido que estos textos sean los de los Diarios de Sesiones, y no otra cosa 😂
Análisis de Sentimiento
Me costó un poquito más encontrar un diccionario en español que tuviera sentimiento, pero encontré éste que es el que voy a usar.
Levanto el diccionario, que llamo lexicon (lo levanto de mi repositorio de GitHub para asegurarme de que siempre esté disponible).
library(readr)
url_lexicon <- 'https://raw.githubusercontent.com/d4tagirl/uruguayan_parliamentary_session_diary/master/SpanishSentimentLexicons/fullStrengthLexicon.txt'
lexicon <- read_tsv(url(url_lexicon),
col_names = FALSE) %>%
select(X1, X3) %>%
rename(palabra = X1, sentimiento = X3)
Este diccionario tiene 1347 palabras, 476 positivas y 871 negativas. Podemos decir que es un diccionario bastante negativo. Es importante para después analizar los resultados, saber si es balanceado o no un diccionario.
tidy_diputados <- diputados %>%
tidytext::unnest_tokens(word, pdf) %>%
filter(!word %in% stopwords)
tidy_diputados %>%
inner_join(lexicon, by = c("word" = "palabra")) %>%
count(word, sentimiento, sort = TRUE) %>%
ungroup() %>%
group_by(sentimiento) %>%
top_n(20) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentimiento)) +
geom_col(show.legend = FALSE) +
scale_fill_viridis(discrete = TRUE) +
facet_wrap(~sentimiento, scales = "free_y") +
labs(y = NULL, x = NULL) +
coord_flip() +
ggtitle("Palabras con sentimientos más extremos en\nsesiones de Diputados") +
theme_minimal()
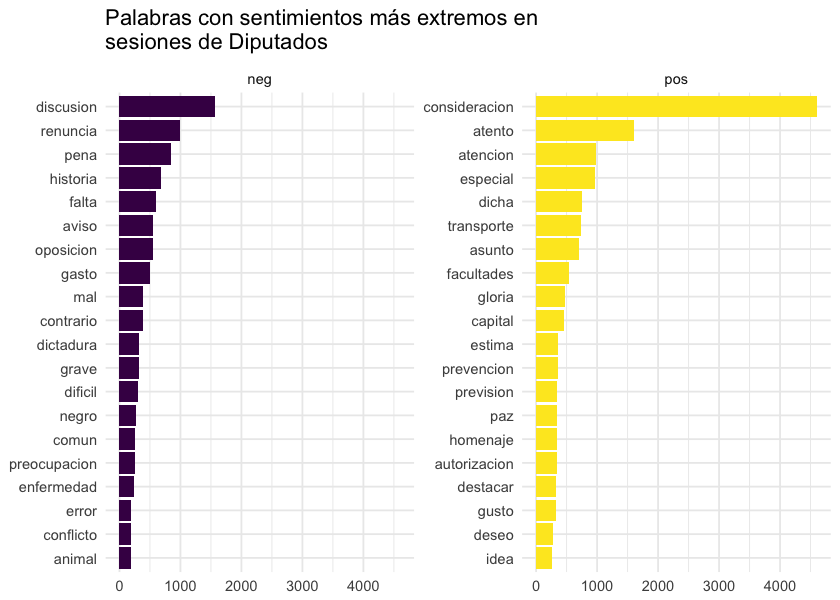
Hay algunas palabras que aparecen con una carga de sentimiento que, dado el contexto, no es apropiado que la tengan. Por ejemplo: “consideracion”, “especial” o “atención”. Y otras con las que no estoy de acuerdo, como que la palabra “negro” esté clasificada como negativa. Así que las agrego como stopwords así no las considero.
stopwords_personalizadas <- c(stopwords, "negro", "discusion", "atento", "consideracion",
"especial", "dicha", "facultades", "atencion", "asunto")
tidy_diputados <- diputados %>%
tidytext::unnest_tokens(word, pdf) %>%
filter(!word %in% stopwords_personalizadas)
tidy_diputados %>%
inner_join(lexicon, by = c("word" = "palabra")) %>%
count(word, sentimiento, sort = TRUE) %>%
ungroup() %>%
group_by(sentimiento) %>%
top_n(20) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentimiento)) +
geom_col(show.legend = FALSE) +
scale_fill_viridis(discrete = TRUE) +
facet_wrap(~sentimiento, scales = "free_y") +
labs(y = NULL, x = NULL) +
coord_flip() +
theme_minimal()
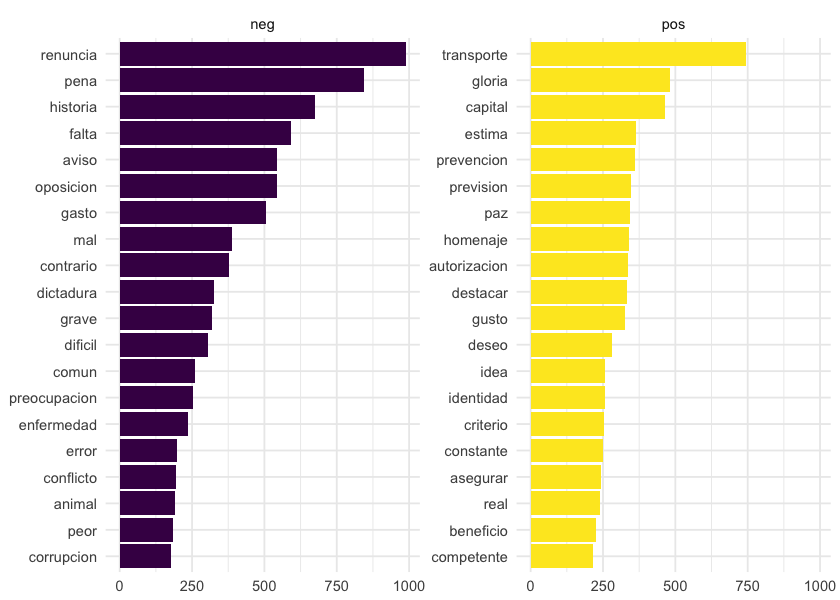
Acá están las 20 palabras más usadas por Diputados, separadas por sentimiento en negativas y positivas. Ahora tiene más sentido, sobre todo para los que vivimos en Uruguay. Que la primera palabra sea renuncia, cuando en setiempre de 2017 renunció el Vice Presidente de la República, tiene mucho sentido! No estoy del todo conforme con las palabras positivas, porque transporte no me queda claro que sea positivo, pero lo voy a dejar así.
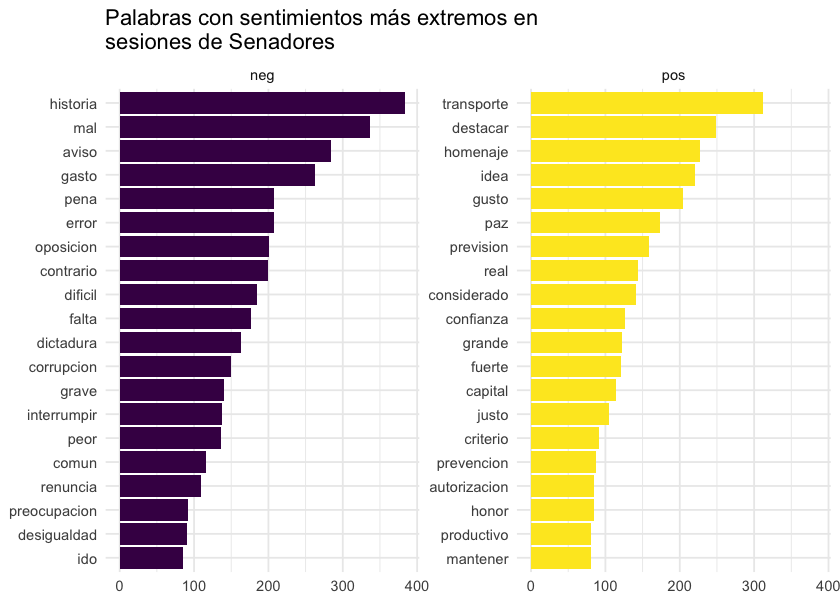
A continuación las palabras más usadas por Senadores, separadas por sentimiento.
Sentimiento en los distintos meses
Separo por mes y veo el sentimiento en los distintos meses. Este análisis lo hago para ver cómo fue era el clima en los distintos momentos del año, y después lo voy a mirar por sesiones.
Para Diputados:
library(tidyr)
tidy_diputados %>%
inner_join(lexicon, by = c("word" = "palabra")) %>%
group_by(mes = as.yearmon(fecha)) %>%
count(sentimiento) %>%
ungroup %>%
spread(sentimiento, n, fill = 0) %>%
mutate(sentimiento = pos - neg) %>%
arrange(mes) %>%
ggplot(aes(as.factor(mes), sentimiento)) +
geom_col(aes(fill = sentimiento > 0), show.legend = FALSE) +
theme_minimal() +
theme(axis.title.x=element_blank(), axis.text.x = element_text(angle=45,
hjust = 1,
vjust = 1)) +
scale_fill_viridis(discrete = TRUE)
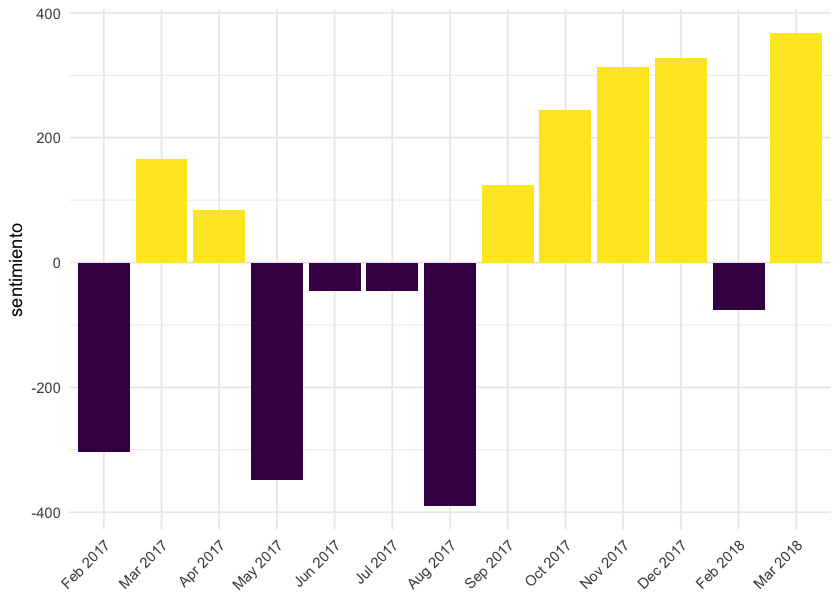
Parece haber una mejora del clima en setiembre, que coincide con la renuncia del Vice Presidente Raúl Sendic 😱
Para senadores:
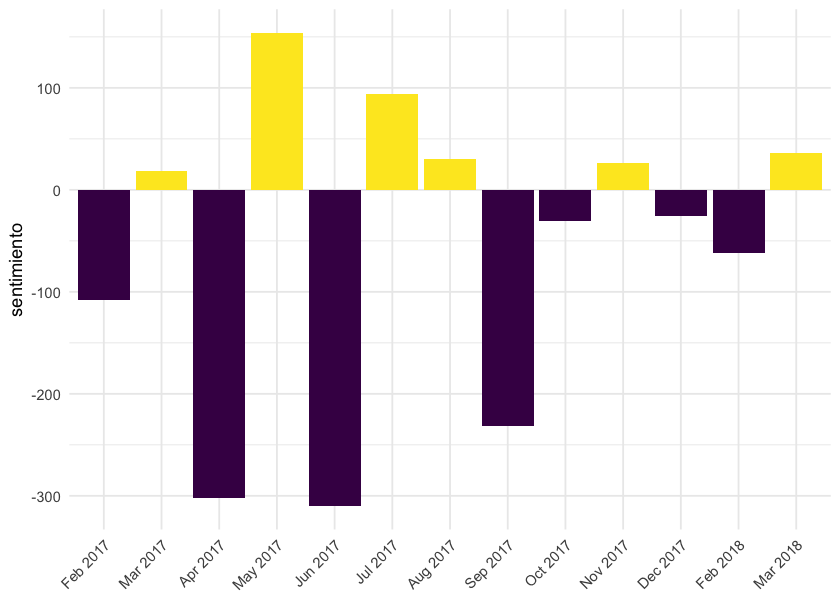
Para las sesiones de Senadores no se observa un comportamiento similar al de las de Diputados 🤷🏽 ♂️
Sentimiento en las distintas sesiones
Me voy a enfocar en las sesiones con sentimientos más extremos. Para eso agrupo por fecha_sesion, que es una variable que tiene la fecha de la sesión junto con el número de la sesión. Es el identificador único de cada sesión.
Para Diputados: Las sesiones con sentimientos más positivos son las que aparecen a continuación.
library(kableExtra)
knitr::kable(
sesiones_positivas_diputados <- tidy_diputados %>%
inner_join(lexicon, by = c("word" = "palabra")) %>%
group_by(fecha_sesion) %>%
count(sentimiento) %>%
ungroup %>%
spread(sentimiento, n, fill = 0) %>%
mutate(sentimiento = pos - neg) %>%
arrange(desc(sentimiento)) %>%
top_n(2, sentimiento),
format = "html") %>%
kable_styling(full_width = F)
| fecha_sesion | neg | pos | sentimiento |
|---|---|---|---|
| 2018-03-06_2 | 158 | 379 | 221 |
| 2017-12-20_1 | 336 | 506 | 170 |
Y las que tienen sentimiento más negativo las siguientes.
knitr::kable(
sesiones_negativas_diputados <- tidy_diputados %>%
inner_join(lexicon, by = c("word" = "palabra")) %>%
group_by(fecha_sesion) %>%
count(sentimiento) %>%
ungroup %>%
spread(sentimiento, n, fill = 0) %>%
mutate(sentimiento = pos - neg) %>%
arrange(sentimiento) %>%
top_n(-2, sentimiento),
format = "html") %>%
kable_styling(full_width = F)
| fecha_sesion | neg | pos | sentimiento |
|---|---|---|---|
| 2017-05-10_14 | 792 | 360 | -432 |
| 2017-02-15_3 | 788 | 484 | -304 |
Para Senadores: Las sesiones con sentimientos más positivos son las que aparecen a continuación.
| fecha_sesion | neg | pos | sentimiento |
|---|---|---|---|
| 2017-05-16_15 | 52 | 158 | 106 |
| 2017-11-28_44 | 243 | 321 | 78 |
Y las que tienen sentimiento más negativo las siguientes.
| fecha_sesion | neg | pos | sentimiento |
|---|---|---|---|
| 2017-09-18_32 | 598 | 364 | -234 |
| 2017-06-07_18 | 458 | 242 | -216 |
De qué se habló en las sesiones más negativas?
Una de las formas de averiguar ésto es calculando el tf-idf. La explicación a continuación es una traducción casi literal de la explicación en inglés del libro “Text mining with R: a tidy approach”, de Julia Silge y David Robinson, libro que recomiendo.
Una medida de qué tan importante es una palabra en una sesión parlamentaria es el term frequency (tf) (frecuencia del término), que mide qué tan frecuentemente aparece una palabra en la sesión. Sin embargo, hay palabras que se pueden repetir mucho pero no ser importantes, como las stopwords que mencionábamos anteriormente, las palabras “protocolares” que en cada sesión se repiten y los nombres de los legisladores. Podríamos eliminarlas como hicimos antes, pero podría ser que alguna de ellas fuera más importante en algunas sesiones que en otras, por ejemplo, si un legislador tiene mayor protagonismo en una sesión por alguna razón.
Otro enfoque entonces es mirar el inverse document frequency (idf) de cada palabra (el inverso de la frecuencia del documento), que reduce el peso a las palabras comúnmente usadas en el total de las sesiones y aumenta el de las que no son muy usadas. Combinando esta medida con el term frquency, calculamos el tf-idf de una palabra (multiplicando ambas medidas): la frecuencia del término, ajustada por qué tan raramente es usada. Con el estadístico tf-idf intento medir qué tan importante es una palabra para una sesión, en el conjunto de sesiones que estoy analizando.
Calculo el tf-idf de las palabras para cada fecha_sesion, usando la función tidytext::bind_tf_idf().
Para Diputados:
sesion_diputados_words <- diputados %>%
unnest_tokens(word, pdf) %>%
count(fecha, sesion, fecha_sesion, word, sort = TRUE) %>%
ungroup()
diputados_words <- sesion_diputados_words %>%
group_by(fecha_sesion) %>%
summarize(total = sum(n))
sesion_diputados_tfidf <- left_join(sesion_diputados_words, diputados_words) %>%
bind_tf_idf(word, fecha_sesion, n)
Acá tengo todos los tf-idf calculados para todas las sesiones. Filtrando sólo las sesiones más negativas, esto es lo que encuentro.
sesion_diputados_tfidf_neg <- sesion_diputados_tfidf %>%
filter(fecha_sesion %in% sesiones_negativas_diputados$fecha_sesion)
sesion_diputados_tfidf_neg %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
group_by(fecha_sesion) %>%
top_n(15, tf_idf) %>%
ungroup %>%
ggplot(aes(word, tf_idf, fill = fecha_sesion)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
scale_fill_viridis(discrete = TRUE, option="C") +
facet_wrap(~fecha_sesion, ncol = 2, scales = "free") +
ggtitle("tf-idf sesiones de Diputados más negativas") +
coord_flip() +
theme_minimal()
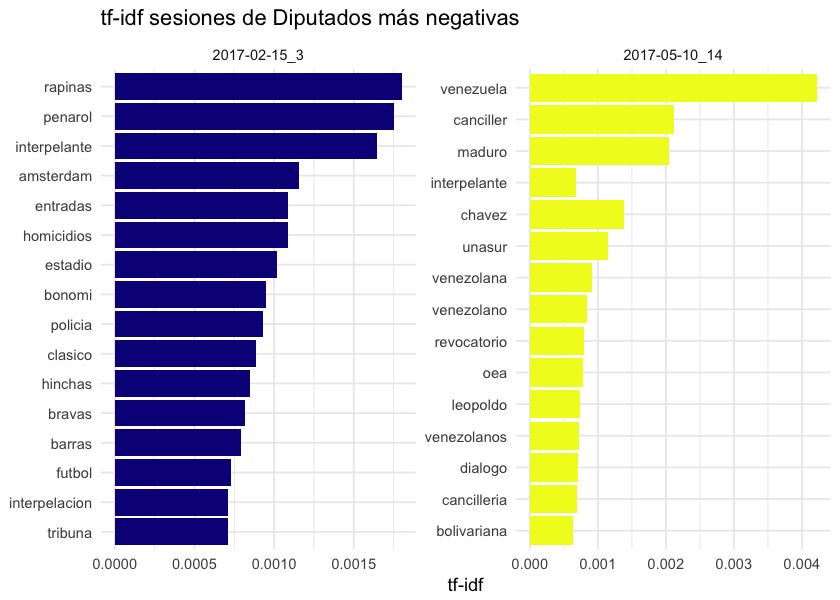
Las dos sesiones más negativas de Diputados fueron dos interpelaciones: la interpelación al Ministro del Interior Eduardo Bonomi que comentaba antes, y la interpelación al canciller Nin Novoa por la posición a adoptar ante la crisis venezolana.
Para Senadores:
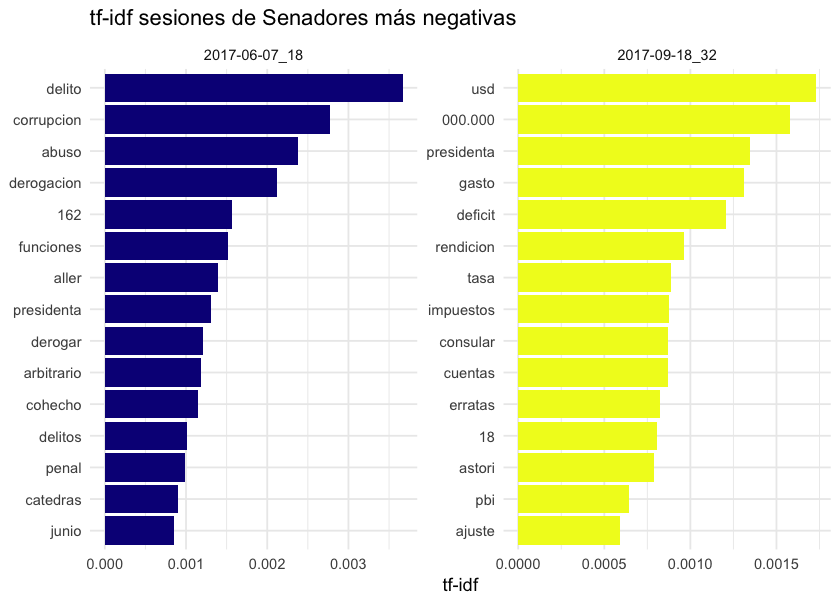
Las sesiones más negativas de los Senadores son:
-
7 de junio de 2017: se votó la derogación de un artículo del Código Penal referido al Abuso de Funciones en casos no previstos especialmente por la ley.
-
18 de setiembre de 2017: se discutió el proyecto de ley para aprobar la Rendición de Cuentas y Balance de Ejecución Presupuestal correspondiente al ejercicio 2016.
Podés ver acá el top 15 de las palabras con mayor tf-idf de todas las sesiones de ambas Cámaras.
Fin!
Hay muchas más cosas que se pueden analizar, éstas fueron las que más me interesaron y por eso las comparto. El análisis completo está en GitHub.
Si querés analizar las sesiones fuera de R, o preferís ahorrarte el paso de hacer scraping, acá tenés las sesiones de Diputados en formato csv, y acá las sesiones de Senadores en formato csv para hacer tus análisis! (Gracias Rodrigo por la sugerencia!)
Bienvenidas todas las sugerencias y comentarios!