Uruguay, el país de los nombres raros?
Aug 13, 2017 · 3572 words · 17 minute read
Hace unos años surgió en Uruguay DATA, una organización de la sociedad civil que trabaja en la promoción y el uso de datos abiertos en Uruguay. Falta mucho camino por recorrer todavía, pero ya existe un conjunto de 146 datasets, incluyendo uno acerca de la producción de cerveza artesanal en Uruguay, que seguramente sea mi próximo desafío con datos abiertos 🍻
Siempre se dice que los uruguayos somos muy creativos para ponerle nombre a nuestros hijos (algo que llama mucho la atención sobre todo a los argentinos, como se menciona en esta nota de Página 12). Los criterios del Registro Civil para registrar los nombres son bastante laxos y eso deja mucho lugar a la discrecionalidad de los padres. Cuando ví estos que estaban estos datos disponibiles, enseguida me puse a ver qué encontraba!
Si querés jugar con los datos acá está la Shiny app que hice donde podés graficar nombres, fijarte los más usados en distintos rangos de años y ver cuáles tuvieron crecimiento excepcional en algún período en particular! A mi por ejemplo me gusta mucho ver qué pasó cuando algún personje se hizo famoso, porque en general impacta en la cantidad de registros de esos años.
Cargando los datos
Lo primero que hago es levantar los datos. Estos datos están disponibles en el sitio de datos abiertos, pero yo los levanto de mi repositorio de GitHub para asegurarme de tenerlos siempre disponibles. Es importante tener en cuenta que se trata de una base del Registro Civil de Montevideo, así que no es representativo de todo el país.
library(readr)
library(dplyr)
url_csv <- 'https://raw.githubusercontent.com/d4tagirl/uruguayan_names/master/nombre_nacim_x_anio_sexo.csv'
nombres_orig <- read_csv(url(url_csv),
col_names = FALSE,
col_types = cols(X2 = col_factor(levels = c("F", "M")))) %>%
rename(año = X1,
sexo = X2,
nombre = X3,
frec = X4)
Renombro las columnas porque no tenían cabezal y miro lo que hay en las primeras filas.
library(knitr)
knitr::kable(head(nombres_orig[c(1:5),]), format = "html",
table.attr = "style='width:30%;'")
| año | sexo | nombre | frec |
|---|---|---|---|
| 1940 | F | MARIA | 1018 |
| 1940 | F | ANA | 208 |
| 1940 | F | GLADYS | 169 |
| 1940 | F | MARIA DEL | 153 |
| 1940 | F | MARTHA | 148 |
La tabla tiene una fila por cada combinación de año-sexo-nombre.
Limpiando los datos
Después limpio los datos.
library(stringi)
nombres <- nombres_orig %>%
mutate(nombre = stri_trans_general(trimws(nombre), id = "latin-ascii"),
nombre = stri_replace_all_regex(nombre, pattern = "[^a-zA-Z ]", "")) %>%
filter(nombre != "",
año != 2012) %>%
group_by(nombre, año) %>%
summarise(frec = sum(frec)) %>%
ungroup()
Con trimws saco los espacios en blanco antes y después del nombre, y con stringi::stri_trans_general() y la opción id = "latin-ascii" les saco los acentos y las ñs que siempre son complicadas! Hay nombres con errores de tipeo, números y otras cosas que no deberían haber en un nombre, así que usando stringi::stri_replace_all_regex() y la expresión regular pattern = "[^a-zA-Z ]" me quedo sólo con letras y espacios.
Después elimino los nombres que quedaron vacíos y elimino los datos de 2012 porque sólo están hasta la mitad del año.
En las 3 últimas líneas lo que hago es remplazar la columna frec por el nuevo cálculo de la frecuencia de cada nombre en el año, que seguramente haya cambiado después de todos los cambios que hice.
En este paso me deshice de la columna sexo, porque tengo la impresión de que no es del todo confiable. Es probable que lo sea, pero por las dudas prefiero excluirla. Quizás más adelante retome esto y la incluya.
Lo que me queda es algo como esto:
library(knitr)
knitr::kable(head(nombres[c(1:5),]), format = "html",
table.attr = "style='width:30%;'")
| nombre | año | frec |
|---|---|---|
| AAERYN | 2002 | 1 |
| AAJONATHAN | 1997 | 1 |
| AALICIA | 1944 | 1 |
| AALMITA | 1940 | 1 |
| AAMELIA | 2000 | 1 |
Vemos ya algunos nombres que llaman la atención… serán errores de tipeo o se llamarán así? 🤔 De todas formas para el análisis posterior excluyo los nombres que tienen baja frecuencia, así que no es un problema.
Transformación de los datos
Ahora que ya estoy contenta con el formato de los datos, empiezo a transformarlos para responder algunas preguntas que me interesan.
library(tidyr)
nombres_año <- nombres %>%
complete(nombre, año, fill = list(frec = 0)) %>%
group_by(nombre) %>%
mutate(total_nombre = sum(frec)) %>%
ungroup() %>%
mutate(porc_nombre = frec / total_nombre) %>%
arrange(desc(total_nombre))
Con tidyr::complete(), para cada combinación de nombre-año que no existe, la genero y le agrego en la columna frec el valor 0. De esta forma me aseguro de siempre tener todos los nombres para todos los años. Esto me sirve para poder calcular la variable porc_nombre, que se calcula como la cantidad de personas con ese nombre en el año, en proporción a la cantidad de personas con ese nombre que hay en total (sumando todos los años).
Lo que tengo al final es ésto (sólo están disponibles en esta tabla los 100 primeros resultados):
library(DT)
datatable(nombres_año[c(1:100),], rownames = FALSE,
options = list(pageLength = 5))
Por cada nombre-año tengo:
frec: la cantidad de registros del nombre en ese año,total_nombre: el total de los registos del nombre entre 1940 y 2011,porc_nombre: el porcentaje de registros del nombre en ese año, en proporción con el total de registros del nombre (frec/total_nombre).
Ahora se pone divertido 🤗
Qué nombres son los más usados?
Al interpretar los resultados hay que considerar que si a una persona la registraron con el nombre “María Inés”, seguramente en mi tabla tenga un registro para María, y uno para Inés (digo seguramente porque no encontré ninguna documentación que especificara nada de esto).
Veamos los nombres más usados a lo largo de los 71 años.
library(ggplot2)
library(viridis)
nombres_año %>%
select(nombre, total_nombre) %>%
distinct(nombre, total_nombre) %>%
top_n(20) %>%
ggplot(aes(reorder(nombre, total_nombre), total_nombre, fill = reorder(nombre, total_nombre))) +
geom_col() +
xlab(NULL) +
ylab(NULL) +
coord_flip() +
theme_minimal(base_size = 14) +
theme(legend.position = "none") +
scale_fill_viridis(discrete = TRUE) +
ggtitle("Nombres más frecuentes")
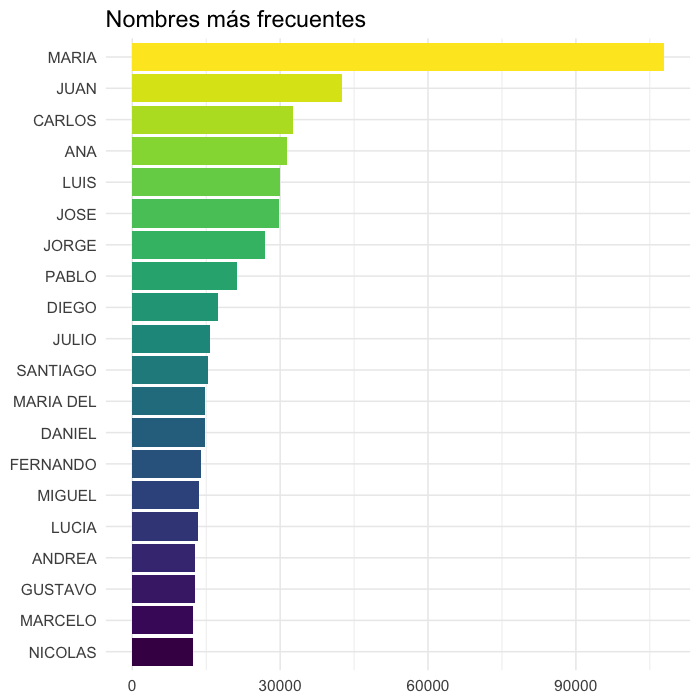
Para los que vivimos bordeando el Río de la Plata estos nombres no nos sorprenden. Lo único que me llama la atención es lo religioso de varios de ellos, siendo Uruguay uno de los países más irreligiosos del mundo.
Veamos en los últimos años (después de 1980 porque nací en 1983 y si tomo algún año posterior me siento vieja 👵 )
nombres_año %>%
filter(año > 1980) %>%
select(nombre, frec) %>%
group_by(nombre) %>%
mutate(total_nombre = sum(frec)) %>%
ungroup() %>%
distinct(nombre, total_nombre) %>%
top_n(20) %>%
ggplot(aes(reorder(nombre, total_nombre), total_nombre, fill = reorder(nombre, total_nombre))) +
geom_col() +
xlab(NULL) +
ylab(NULL) +
coord_flip() +
theme_minimal(base_size = 14) +
theme(legend.position = "none") +
scale_fill_viridis(discrete = TRUE) +
ggtitle("Nombres más frecuentes \ndespués de 1980")
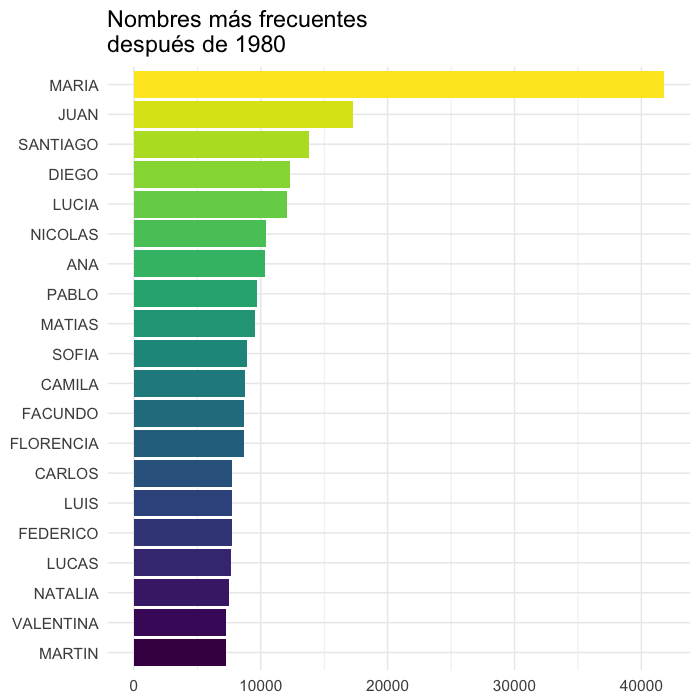
Si bien los nombres del puesto 3 para abajo cambian, y la verdad es que se parecen a nombres de generaciones más jóvenes para nosotros, siguen siendo los más usados María y Juan. María siempre arriba por un margen muy amplio. Es nombre muy usado en nombres compuestos (María del Carmen, María Inés), y puede ser usado para hombre o para mujer (Juan María por ejemplo), así que es muy popular.
No puedo ver las combinaciones de nombres porque sólo tengo para cada nombre individual la cantidad por año, pero sería algo que me gustaría mirar.
Qué nombres son los menos usados?
Si no pongo ninguna restricción de cantidad de personas por nombre, los menos usados son todos nombres que sólo una persona tiene. Y muchos parecen ser errores… aunque quizás no lo sean 😱
nombres_unicos <- nombres_año %>%
select(nombre, total_nombre) %>%
distinct(nombre, total_nombre) %>%
filter(total_nombre == 1)
library(DT)
datatable(nombres_unicos, rownames = FALSE,
options = list(pageLength = 5))
Arbitrariamente puse un límite de 200 personas con un nombre para considerarlo, y ahí me fijé los menos populares a ver qué tan exóticos son.
library(here)
nombres_año %>%
select(nombre, total_nombre) %>%
distinct(nombre, total_nombre) %>%
filter(total_nombre > 200) %>%
top_n(-20) %>%
ggplot(aes(reorder(nombre, total_nombre), total_nombre, fill = reorder(nombre, total_nombre))) +
geom_col() +
xlab(NULL) +
ylab(NULL) +
coord_flip() +
theme_minimal(base_size = 14) +
theme(legend.position = "none") +
scale_fill_viridis(discrete = TRUE) +
ggtitle("Nombres menos frecuentes")
ggsave(filename = here("", "nombres_menos_usados.png"), width = 5, height = 4, dpi = 140)
library(magick)
grafico <- image_read(here("", "nombres_menos_usados.png"))
gif <- image_read(here("", "confused_2.gif"))
frames <- lapply(gif, function(frame) {
image_composite(grafico, frame, offset = "+70+30")
})
image_animate(image_join(frames))

Algo podemos decir es que nos gustan los nombres anglosajones, aunque la forma de escribirlos tiene sus toques locales! La verdad es que tenemos nombres raros 🤷🏻 ♀️
Pero… hablemos de lo que acabo de hacer… no está buenísima la animación?? Para los que les interese acá van mis comentarios, y para los que no, pueden seguir por acá nomás!
La idea surgió de un artículo de Daniel Hadley donde muestra el código para hacer una animación como la que acabo de hacer. El paquete here lo único que hace es permitirnos olvidarnos de las rutas, así que no voy a entrar mucho en detalles. Pero el paquete magick de rOpenSci es el que hace la magia ✨ (era de sospecharse, con ese nombre!). Interpreta en grafico la imagen del plot que guardé con ggsave() y en gif cada cuadro del archivo .gif que elegí. Acá hay un secreto: todos los cuadros del archivo .gif tienen que tener el mismo tamaño, si no la imagen termina rebotando para todos lados! Esto me llevó mucho rato (y frustración!), hasta que Gervasio se dio cuenta! Usando esta página pude cambiar el .gif, usando la opción de optimize/coalesce. Y quedó bárbaro!
Los nombres que más crecieron y más decrecieron
Para ver cuáles fueron los nombres que más crecieron y los que más decrecieron lo que hago es estimar una regresión lineal de cada nombre, explicada por el año. Para hacer ésto uso dataframes anidados, que genero con tidyr::nest(). De nuevo, los que no tengan ganas de leer estas explicaciones pueden seguir acá.
library(tidyr)
library(purrr)
library(broom)
pendientes <- nombres_año %>%
filter(total_nombre > 1000) %>%
group_by(nombre) %>%
nest(-nombre) %>%
mutate(modelo = map(data, ~ lm(porc_nombre ~ año, .))) %>%
unnest(map(modelo, tidy)) %>%
filter(term == "año") %>%
mutate(p.adjusted = p.adjust(p.value)) %>%
filter(p.adjusted < .05) %>%
arrange(desc(estimate))
Me quedo con los nombres que fueron registrados al menos 800 veces en los 71 años (creo que esto no es muy exigente, en promedio tiene que haber sido usado menos de 15 veces por año!). Cuando hago nest(-nombre) genero un dataframe que tiene 2 columnas: la primera es nombre, y la segunda es data. Lo más curioso es la columna data, porque cada elementos de la columna son dataframes chiquititos, con la información agrupada por nombre.
Entonces para cada nombre tengo un dataframe, que tiene como columnas: año, frec, total_nombre y porc_nombre; y cada fila representa un año diferente. Esto me permite poder ajustar un modelo distinto para cada nombre. Después aplico la función map::purrr() a cada dataframe (a cada nombre) para que le ajuste un modelo lineal, que especifico con map(data, ~ lm(porc_nombre ~ año, .)). Después extraigo los resultados del modelo con broom::tidy() y me quedo sólo con el coeficiente correspondiente a año. Me quedo sólo con los que tienen un p-valor ajustado menor a 0.05.
head(pendientes, 12) %>%
bind_rows(tail(pendientes, 12)) %>%
ggplot(aes(reorder(nombre, estimate), estimate, fill = reorder(nombre, estimate))) +
geom_col(aes(fill = estimate > 0), show.legend = FALSE) +
xlab(NULL) +
ylab(NULL) +
coord_flip() +
theme_minimal() +
scale_fill_manual(values = c("red", "green")) +
ggtitle("Nombres que más crecieron y decrecieron") +
labs(caption = "los que más crecieron ---->")
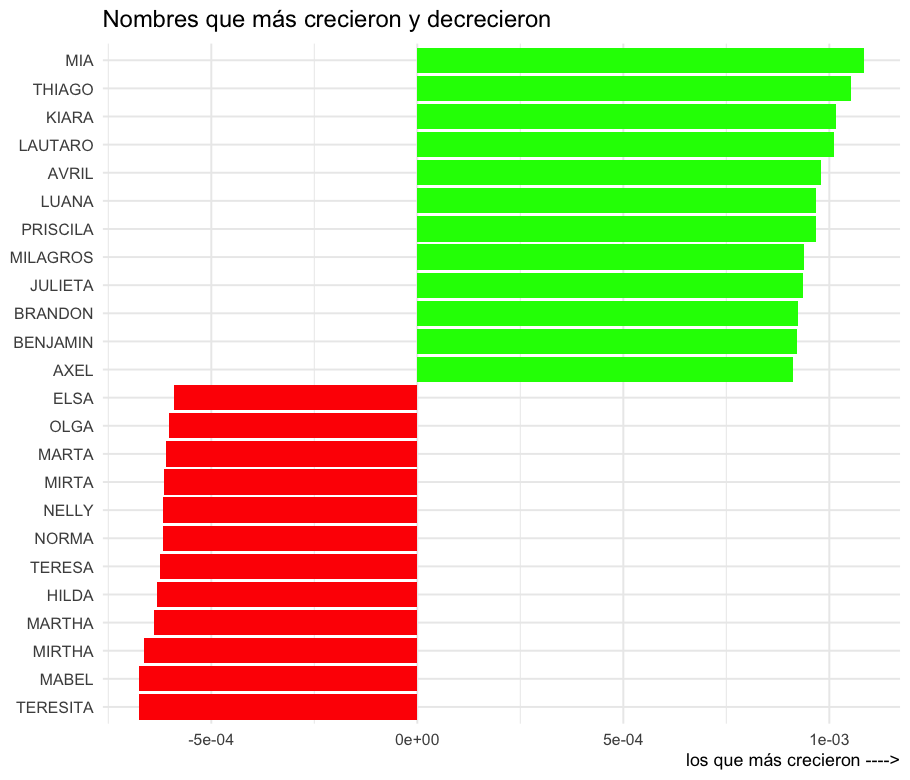
Acá se ven los nombres que más crecieron y los que menos. Una vez más, para los locales no hay novedades porque los nombres en verde son los asociados a las nuevas generaciones y los rojos los asociados a las menos nuevas.
Los nombres que tuvieron crecimientos exepcionales
Para hacer esto me basé en el artículo de David Robinson donde analiza las tendencias de los términos usados en Hacker News.
De la misma forma que ajusté una regresión lineal para cada nombre, ahora ajusto una spline cúbica. (Pueden saltearse ésto acá)
library(splines)
spline_prediccion <- nombres_año %>%
filter(total_nombre > 800) %>%
nest(-nombre) %>%
mutate(modelo = map(data, ~ glm(porc_nombre ~ ns(año, 4), ., family = "binomial"))) %>%
unnest(map2(modelo, data, augment, type.predict = "response"))
Después comparo la máxima predicción de esa spline cúbica: .fitted con el promedio de todas las predicciones average y calculo el ratio como la predicción máxima para cada nombre sobre el promedio. Selecciono a los 12 con ratio más grande y los grafico.
spline_prediccion %>%
group_by(nombre) %>%
mutate(average = mean(.fitted)) %>%
top_n(1, .fitted) %>%
ungroup() %>%
mutate(ratio = .fitted / average) %>%
top_n(12, ratio) %>%
select(nombre) %>%
inner_join(nombres_año) %>%
ggplot(aes(año, frec, color = nombre)) +
geom_line() +
facet_wrap( ~ reorder(nombre, desc(frec))) +
ggtitle("Evolución de los nombres con crecimientos excepcionales \n") +
theme_minimal() +
theme(legend.position = "none", axis.title.x = element_blank(),
axis.title.y = element_blank())
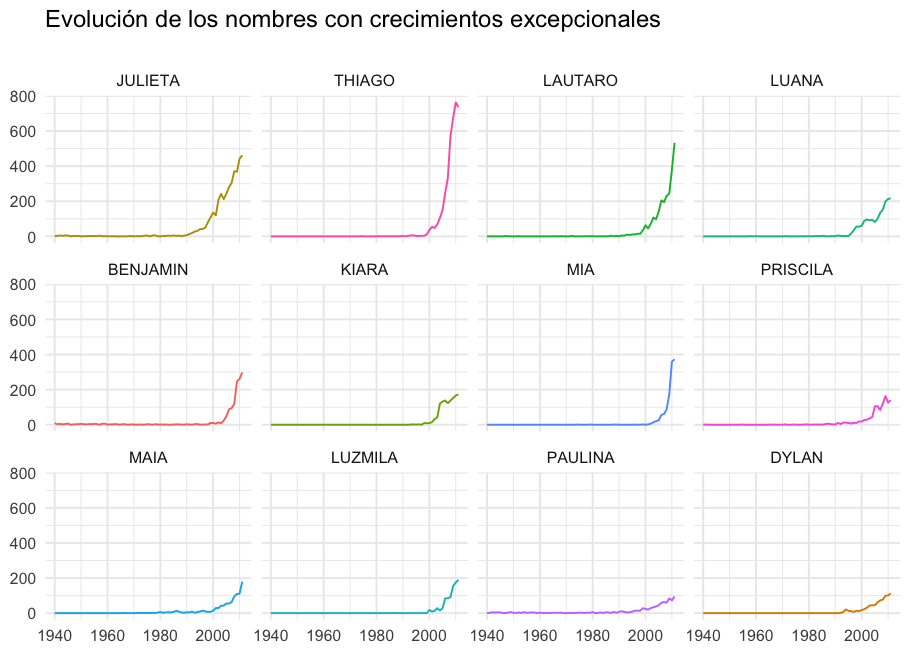
Los picos más pronunciados se dieron siempre en los últimos años. Podés hacer este mismo análisis pero considerando diferentes rangos de años en la Shiny app.
Hay nombres que crecen porque hay algún personaje que se hace famoso?
Una teoría que siempre ronda por ahí es que cuando hay alguna telenovela nueva, aumentan los registros de nombres relacionados por ejemplo, al actor o actriz principal. Podemos contrastar esto ahora! Voy a tomar el caso de Agustina, que es el nombre de pila de la actríz que hacía de “Mili” en “Chiquititas” (Agustina Cherri). Chiquititas es una telenovela argentina infantil, que fue furor desde que empezó en 1995 y duró 7 temporadas. Yo nunca la miré pero todas mis amigas la miraban 📺
nombres_año %>%
filter(nombre == "AGUSTINA") %>%
ggplot(aes(año, frec, colour = nombre,
text = paste('año: ', año,
'<br /> cantidad : ', frec))) +
geom_line(group = 1) +
geom_point(size = 0.1) +
geom_vline(xintercept = 1995) +
scale_x_continuous(breaks = c(1940, 1960, 1980, 1995, 2000)) +
ggtitle("Cantidad de Agustinas nacidas por año \n") +
theme_minimal() +
theme(axis.title.x = element_blank(), axis.title.y = element_blank(),
axis.line = element_line(colour = "grey"), legend.title = element_blank(),
legend.position = 'none', plot.title = element_text(hjust = 0.5),
panel.grid.major = element_blank(), panel.border = element_blank())
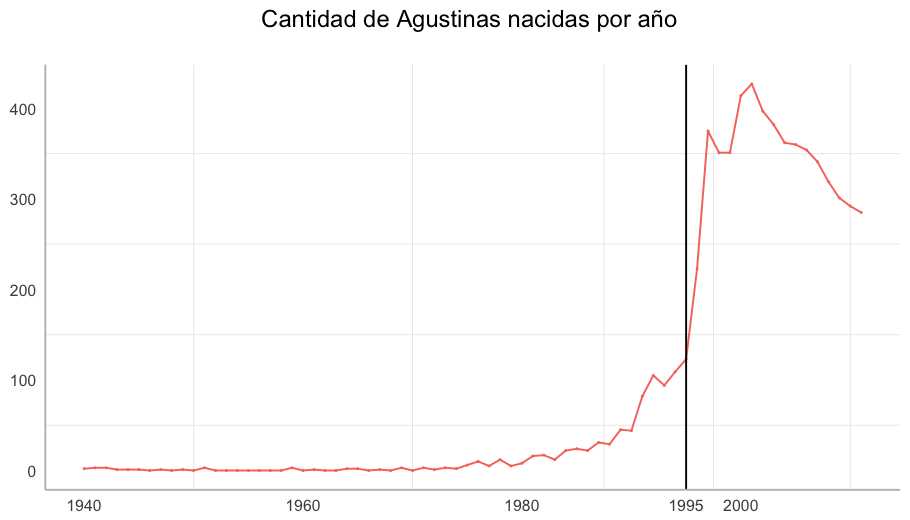
Para ver otros nombres (yo tengo muy mala memoria!) también lo podés hacer en esta Shiny.
Cada vez hay más nombres o es un mito?
Lo último que quiero ver es si nos hemos vuelto más creativos con los años. Para eso analizo la cantidad de nombres que hubo cada año, a ver si aumentó o disminuyó. No estoy tomando en cuenta el efecto del aumento de la población porque la cantidad de nombres registrados que tengo en esta base no se refiere a la cantidad de personas registradas, entonces no tengo información suficiente para hacerlo.
nombres %>%
group_by(año) %>%
summarize(total_año = n()) %>%
ggplot(aes(año, total_año, fill = año)) +
geom_col() +
geom_smooth(se = FALSE) +
scale_fill_viridis() +
theme_minimal() +
theme(axis.title.x = element_blank(), axis.title.y = element_blank(),
legend.position = 'none') +
ggtitle("Cantidad de nombres por año")
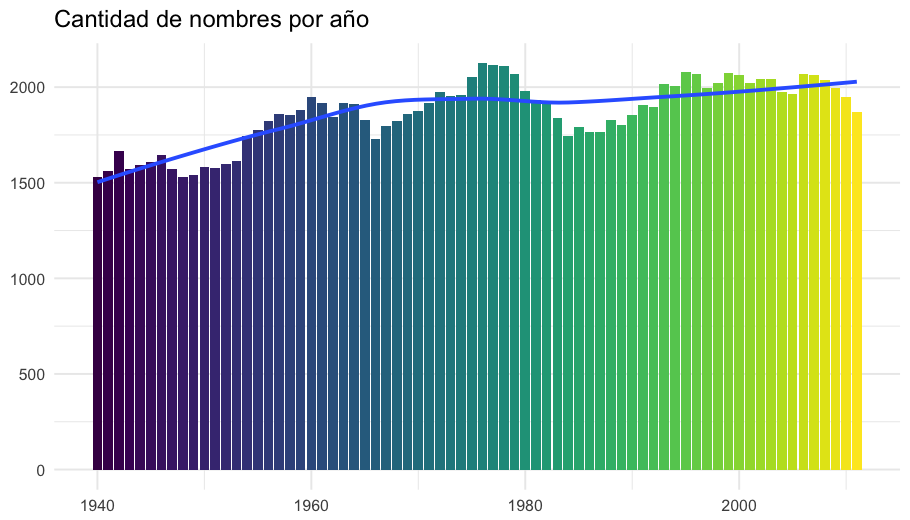
Aumentó de unos 1500 nombres en 1940 a unos 2000 en 2011, no parece tanto! Más si consideramos que la población de Uruguay pasó de ser 2:163.547 en 1940 a ser 3.286.314 en 2011. No quiere decir que no haya nombres creativos, pero para averiguarlo una vez más te propongo que visites la Shiny app 😉
Espero que te haya gustado, a mi me pareció divertidísimo hacerlo!
Como siempre, acá dejo el código del análisis que hice y de la Shiny app.